Definición
Un grafo es un objeto matemático que se utiliza para representar
circuitos, redes, etc. Los grafos son muy utilizados en computación,
ya que permiten resolver problemas muy complejos.
Imaginemos que disponemos de una serie de ciudades y de carreteras
que las unen. De cada ciudad saldrán varias carreteras, por lo que para
ir de una ciudad a otra se podrán tomar diversos caminos. Cada carretera
tendrá un coste asociado (por ejemplo, la longitud de la misma). Gracias
a la representación por grafos podremos elegir el camino más corto
que conecta dos ciudades, determinar si es posible llegar de una ciudad a otra,
si desde cualquier ciudad existe un camino que llegue a cualquier otra, etc.
El estudio de grafos es una rama de la algoritmia muy importante.
Estudiaremos primero sus rasgos generales y sus recorridos fundamentales, para
tener una buena base que permita comprender los algoritmos que se pueden aplicar.
Glosario
Un grafo consta de vértices (o nodos) y aristas.
Los vértices son objetos que contienen información y las aristas
son conexiones entre vértices. Para representarlos, se suelen utilizar
puntos para los vértices y líneas para las conexiones, aunque
hay que recordar siempre que la definición de un grafo no depende de
su representación.
Un camino entre dos vértices es una lista de vértices
en la que dos elementos sucesivos están conectados por una arista del
grafo. Así, el camino AJLOE es un camino que comienza en el vértice
A y pasa por los vértices J,L y O (en ese orden) y al final va del O
al E. El grafo será conexo si existe un camino desde cualquier
nodo del grafo hasta cualquier otro. Si no es conexo constará de varias
componentes conexas.
Un camino simple es un camino desde un nodo a otro en
el que ningún nodo se repite (no se pasa dos veces). Si el camino simple
tiene como primer y último elemento al mismo nodo se denomina ciclo.
Cuando el grafo no tiene ciclos tenemos un árbol (ver árboles).
Varios árboles independientes forman un bosque. Un árbol
de expansión de un grafo es una reducción del grafo en el
que solo entran a formar parte el número mínimo de aristas que
forman un árbol y conectan a todos los nodos.
Según el número de aristas que contiene, un grafo
es completo si cuenta con todas las aristas posibles (es decir, todos
los nodos están conectados con todos), disperso si tiene relativamente
pocas aristas y denso si le faltan pocas para ser completo.
Las aristas son la mayor parte de las veces bidireccionales,
es decir, si una arista conecta dos nodos A y B se puede recorrer tanto en sentido
hacia B como en sentido hacia A: estos son llamados grafos no dirigidos.
Sin embargo, en ocasiones tenemos que las uniones son unidireccionales. Estas
uniones se suelen dibujar con una flecha y definen un grafo dirigido.
Cuando las aristas llevan un coste asociado (un entero al que se denomina peso)
el grafo es ponderado. Una red es un grafo dirigido y ponderado.
Representación de grafos
Una característica especial en los grafos es que podemos
representarlos utilizando dos estructuras de datos distintas. En los algoritmos
que se aplican sobre ellos veremos que adoptarán tiempos distintos dependiendo
de la forma de representación elegida. En particular, los tiempos de
ejecución variarán en función del número de vértices
y el de aristas, por lo que la utilización de una representación
u otra dependerá en gran medida de si el grafo es denso o disperso.
Para nombrar los nodos utilizaremos letras mayúsculas,
aunque en el código deberemos hacer corresponder cada nodo con un entero
entre 1 y V (número de vértices) de cara a la manipulación
de los mismos.
Representación por matriz de adyacencia
Es la forma más común de representación
y la más directa. Consiste en una tabla de tamaño V x V, en que
la que a[i][j] tendrá como valor 1 si existe una arista del nodo i al
nodo j. En caso contrario, el valor será 0. Cuando se trata de grafos
ponderados en lugar de 1 el valor que tomará será el peso de la
arista. Si el grafo es no dirigido hay que asegurarse de que se marca con un
1 (o con el peso) tanto la entrada a[i][j] como la entrada a[j][i], puesto que
se puede recorrer en ambos sentidos.
int V,A;
int a[maxV][maxV];
void inicializar()
{
int i,x,y,p;
char v1,v2;
// Leer V y A
memset(a,0,sizeof(a));
for (i=1; i<=A; i++)
{
scanf("%c %c %d\n",&v1,&v2,&p);
x=v1-'A'; y=v2-'A';
a[x][y]=p; a[y][x]=p;
}
}
En esta implementación se ha supuesto que los vértices
se nombran con una letra mayúscula y no hay errores en la entrada. Evidentemente,
cada problema tendrá una forma de entrada distinta y la inicialización
será conveniente adaptarla a cada situación. En todo caso, esta
operación es sencilla si el número de nodos es pequeño.
Si, por el contrario, la entrada fuese muy grande se pueden almacenar los nombres
de nodos en un árbol binario de búsqueda o utilizar una tabla
de dispersión, asignando un entero a cada nodo, que será el utilizado
en la matriz de adyacencia.
Como se puede apreciar, la matriz de adyacencia siempre ocupa
un espacio de V*V, es decir, depende solamente del número de nodos y
no del de aristas, por lo que será útil para representar grafos
densos.
Representación por lista de adyacencia
Otra forma de representar un grafo es por medio de listas que
definen las aristas que conectan los nodos. Lo que se hace es definir una lista
enlazada para cada nodo, que contendrá los nodos a los cuales es posible
acceder. Es decir, un nodo A tendrá una lista enlazada asociada en la
que aparecerá un elemento con una referencia al nodo B si A y B tienen
una arista que los une. Obviamente, si el grafo es no dirigido, en la lista
enlazada de B aparecerá la correspondiente referencia al nodo A.
Las listas de adyacencia serán estructuras que contendrán
un valor entero (el número que identifica al nodo destino), así
como otro entero que indica el coste en el caso de que el grafo sea ponderado.
En el ejemplo se ha utilizado un nodo z ficticio en la cola (ver listas,
apartado cabeceras y centinelas).
struct nodo
{
int v;
int p;
nodo *sig;
};
int V,A; // vértices y aristas del grafo
struct nodo *a[maxV], *z;
void inicializar()
{
int i,x,y,peso;
char v1,v2;
struct nodo *t;
z=(struct nodo *)malloc(sizeof(struct nodo));
z->sig=z;
for (i=0; i<V; i++)
a[i]=z;
for (i=0; i<A; i++)
{
scanf("%c %c %d\n",&v1,&v2,&peso);
x=v1-'A'; y=v2-'A';
t=(struct nodo *)malloc(sizeof(struct nodo));
t->v=y; t->p=peso; t->sig=a[x]; a[x]=t;
t=(struct nodo *)malloc(sizeof(struct nodo));
t->v=x; t->p=peso; t->sig=a[y]; a[y]=t;
}
}
En este caso el espacio ocupado es O(V + A), muy distinto del
necesario en la matriz de adyacencia, que era de O(V2). La representación
por listas de adyacencia, por tanto, será más adecuada para grafos
dispersos.
Hay que tener en cuenta un aspecto importante y es que la implementación
con listas enlazadas determina fuertemente el tratamiento del grafo posterior.
Como se puede ver en el código, los nodos se van añadiendo a las
listas según se leen las aristas, por lo que nos encontramos que un mismo
grafo con un orden distinto de las aristas en la entrada producirá listas
de adyacencia diferentes y por ello el orden en que los nodos se procesen variará.
Una consecuencia de esto es que si un problema tiene varias soluciones la primera
que se encuentre dependerá de la entrada dada. Podría presentarse
el caso de tener varias soluciones y tener que mostrarlas siguiendo un determinado
orden. Ante una situación así podría ser muy conveniente
modificar la forma de meter los nodos en la lista (por ejemplo, hacerlo al final
y no al principio, o incluso insertarlo en una posición adecuada), de
manera que el algoritmo mismo diera las soluciones ya ordenadas.
Exploración de grafos
A la hora de explorar un grafo, nos encontramos con dos métodos
distintos. Ambos conducen al mismo destino (la exploración de todos los
vértices o hasta que se encuentra uno determinado), si bien el orden
en que éstos son "visitados" decide radicalmente el tiempo
de ejecución de un algoritmo, como se verá posteriormente.
En primer lugar, una forma sencilla de recorrer los vértices
es mediante una función recursiva, lo que se denomina búsqueda
en profundidad. La sustitución de la recursión (cuya base es la
estructura de datos pila) por una cola
nos proporciona el segundo método de búsqueda o recorrido, la
búsqueda en amplitud o anchura.
Suponiendo que el orden en que están almacenados los nodos
en la estructura de datos correspondiente es A-B-C-D-E-F... (el orden alfabético),
tenemos que el orden que seguiría el recorrido en profundidad sería
el siguiente:
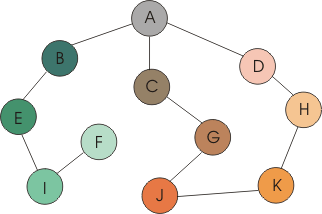
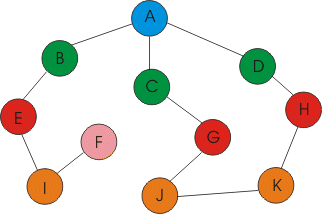
A-B-E-I-F-C-G-J-K-H-D
En un recorrido en anchura el orden sería, por contra:
A-B-C-D-E-G-H-I-J-K-F
Es decir, en el primer caso se exploran primero los verdes y
luego los marrones, pasando primero por los de mayor intensidad de color. En
el segundo caso se exploran primero los verdes, después los rojos, los
naranjas y, por último, el rosa.
Es destacable que el nodo D es el último en explorarse
en la búsqueda en profundidad pese a ser adyacente al nodo de origen
(el A). Esto es debido a que primero se explora la rama del nodo C, que también
conduce al nodo D.
En estos ejemplos hay que tener en cuenta que es fundamental
el orden en que los nodos están almacenados en las estructuras de datos.
Si, por ejemplo, el nodo D estuviera antes que el C, en la búsqueda en
profundidad se tomaría primero la rama del D (con lo que el último
en visitarse sería el C), y en la búsqueda en anchura se exploraría
antes el H que el G.
Búsqueda en profundidad
Se implementa de forma recursiva, aunque también puede
realizarse con una pila. Se utiliza un array val
para almacenar el orden en que fueron explorados los vértices. Para ello
se incrementa una variable global id (inicializada
a 0) cada vez que se visita un nuevo vértice y se almacena id
en la entrada del array val correspondiente
al vértice que se está explorando.
La siguiente función realiza un máximo de V (el
número total de vértices) llamadas a la función visitar,
que implementamos aquí en sus dos variantes: representación por
matriz de adyacencia y por listas de adyacencia.
int id=0;
int val[V];
void buscar()
{
int k;
for (k=1; k<=V; k++)
val[k]=0;
for (k=1; k<=V; k++)
if (val[k]==0) visitar(k);
}
void visitar(int k) // matriz de adyacencia
{
int t;
val[k]=++id;
for (t=1; t<=V; t++)
if (a[k][t] && val[t]==0) visitar(t);
}
void visitar(int k) // listas de adyacencia
{
struct nodo *t;
val[k]=++id;
for (t=a[k]; t!=z; t=t->sig)
if (val[t->v]==0) visitar(t->v);
}
El resultado es que el array val
contendrá en su i-ésima entrada el orden en el que el vértice
i-ésimo fue explorado. Es decir, si tenemos un grafo con cuatro nodos
y fueron explorados en el orden 3-1-2-4, el array val
quedará como sigue:
val[1]=2; // el primer nodo fue visto en segundo lugar
val[2]=3; // el segundo nodo fue visto en tercer lugar
val[3]=1; // etc.
val[4]=4;
Una modificación que puede resultar especialmente útil
es la creación de un array "inverso" al array val
que contenga los datos anteriores "al revés". Esto es, un array
en el que la entrada i-ésima contiene el vértice que se exploró
en i-ésimo lugar. Basta modificar la línea
val[k]=++id;
sustituyéndola por
val[++id]=k;
Para el orden de exploración de ejemplo anterior los valores
serían los siguientes:
val[1]=3;
val[2]=1;
val[3]=2;
val[4]=4;
Búsqueda en amplitud o anchura
La diferencia fundamental respecto a la búsqueda en profundidad
es el cambio de estructura de datos: una cola en lugar
de una pila. En esta implementación, la función del array val
y la variable id es la misma que en el método
anterior.
struct tcola *cola;
void visitar(int k) // listas de adyacencia
{
struct nodo *t;
encolar(&cola,k);
while (!vacia(cola))
{
desencolar(&cola,&k);
val[k]=++id;
for (t=a[k]; t!=z; t=t->sig)
{
if (val[t->v]==0)
{
encolar(&cola,t->v);
val[t->v]=-1;
}
}
}
}
|